Your sitemap is the single most important file you hand to Google, and most SEO professionals treat it like an afterthought. That's a problem. When Googlebot arrives at your XML sitemap, it doesn't just glance at the URLs and move on. It parses structure, evaluates freshness signals, checks HTTP status codes, and decides which pages deserve crawl budget.
If your sitemap contains errors, broken links, or invalid XML, you're actively sabotaging your own indexing pipeline. The professionals who run a sitemap error checker before submitting to Google Search Console consistently outperform those who don't. Technical SEO starts here, with validation, and ignoring it costs you rankings you've already earned. Understanding how to scan and validate your XML sitemap for errors is the foundation for everything I'm about to argue.
Key Takeaways
- Google's crawler treats your sitemap as a prioritized crawl queue, not a guaranteed index list.
- Sitemap errors like malformed XML or broken URLs waste crawl budget on dead ends.
- Validation before submission catches problems that Google Search Console reports too late.
- Crawl frequency and page discovery depend heavily on accurate lastmod and priority signals.
- Regular sitemap audits reduce indexing delays and protect against silent ranking losses.
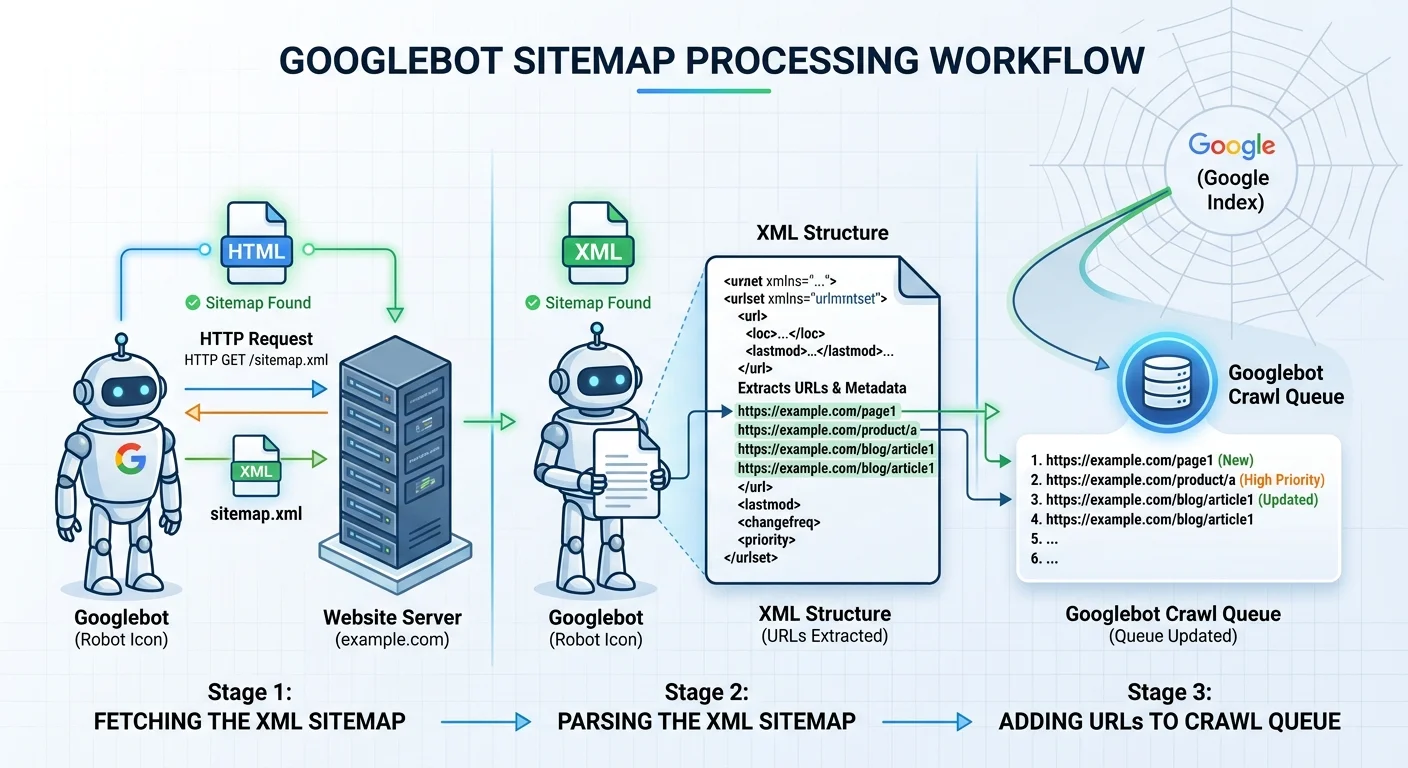
How Googlebot Actually Processes Your Sitemap
The Fetch-Parse-Queue Cycle
When Googlebot discovers your sitemap (either through robots.txt, Search Console submission, or a sitemap index reference), it initiates an HTTP request to fetch the file. The response must return a 200 status code with valid XML content. If the server returns a 404, 500, or even a 301 redirect to a non-XML page, Google logs the failure and moves on. There's no retry queue with infinite patience; your sitemap gets a limited number of chances.
Once fetched, Google's parser reads every <url> element and extracts the <loc>, <lastmod>, <changefreq>, and <priority> tags. The parser is strict about XML well-formedness. A single unclosed tag, an illegal character, or an encoding mismatch can cause the entire sitemap to be rejected. Google has confirmed that it primarily uses <loc> and <lastmod>, but parsing failure means none of your URLs enter the crawl queue at all.
After successful parsing, URLs enter Googlebot's crawl scheduler. This is where many webmasters misunderstand the process. Your sitemap is a suggestion, not a command. Google weighs each URL against factors like site authority, historical crawl data, and server response speed. But here's the critical point: if a URL never enters the scheduler because of a sitemap error, it has zero chance of being prioritized through that channel.
What Google Ignores and Why
Google has publicly stated that it ignores the <priority> tag entirely. The <changefreq> tag receives minimal attention. Yet thousands of sitemaps still stuff these fields with arbitrary values, adding file bloat without crawl benefit. Your time is better spent making sure every <loc> points to a canonical, indexable URL with an accurate <lastmod> timestamp. Anything else is noise that Google filters out before scheduling a single crawl.
Remove
Why Sitemap Errors Silently Destroy Crawl Efficiency
The Real Cost of Broken URLs
A sitemap filled with broken URLs is worse than having no sitemap at all. When Googlebot follows a link from your sitemap and hits a 404 or a redirect chain, it burns crawl budget on a dead end. For large sites with tens of thousands of pages, this waste compounds quickly. Google allocates crawl budget based on perceived site quality, and consistent errors signal that your site isn't well maintained. Learning how to fix broken URLs in your XML sitemap fast is not optional for serious practitioners.
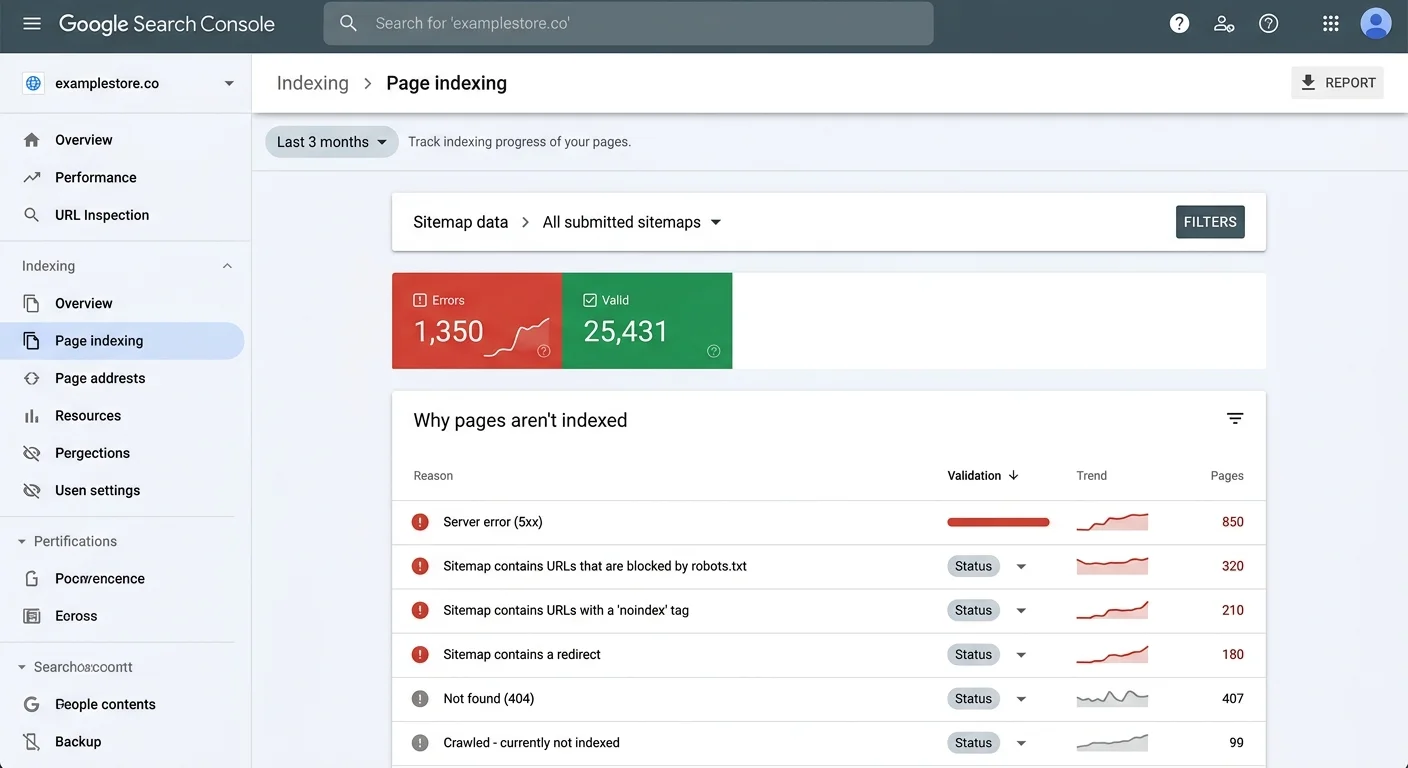
I've personally audited sites where over 15% of sitemap URLs returned non-200 status codes. The site owners had no idea because they never checked. They relied on Google Search Console's coverage report, which only surfaces problems after Google has already wasted time attempting to crawl those pages. The feedback loop is too slow. By the time you see the error in GSC, you've already lost days or weeks of optimal crawl allocation.
Malformed XML Is Worse Than No Sitemap
Malformed XML causes catastrophic parsing failure. One ampersand in a URL that isn't properly encoded as & can break the entire file. One missing closing tag can render 50,000 URLs invisible to Google. This isn't hypothetical. A well-known guide to common XML sitemap errors and how to resolve them documents these exact patterns across thousands of real sites. The fix is usually simple, but the detection requires deliberate effort.
The silent nature of these failures is what makes them dangerous. Google doesn't send you an email saying "your sitemap is broken." It simply stops processing it. Your new pages don't get discovered. Your updated content doesn't get re-crawled. You see organic traffic plateau or decline and blame algorithm updates when the real culprit is a syntax error in line 47 of your sitemap file.
A single XML syntax error can cause Google to reject your entire sitemap, leaving all URLs undiscovered.
| Error Type | Google's Response | Severity | Detection Method |
|---|---|---|---|
| Malformed XML | Entire sitemap rejected | Critical | XML validator |
| 404 URLs | Crawl budget wasted | High | HTTP status checker |
| Redirect chains | Delayed or skipped crawl | Medium | Redirect audit |
| Duplicate URLs | Redundant crawl requests | Medium | Sitemap diff tool |
| Missing lastmod | Lower re-crawl priority | Low | Manual review |
| Non-canonical URLs | Crawl spent on wrong page | High | Canonical tag audit |
The Validation Workflow That Actually Works
Proactive vs. Reactive Error Detection
The difference between a reactive and proactive approach to sitemap validation is measured in weeks of lost indexing. Reactive means waiting for Google Search Console to flag an issue in the coverage report, then scrambling to fix it. Proactive means running your sitemap through a dedicated checker before submission, catching errors before Googlebot ever sees them. The best free sitemap validation tools for technical SEO make proactive checking straightforward.
"If you validate your sitemap only after Google reports a problem, you've already lost crawl cycles you can never recover."
Google provides several of its own tools worth using alongside third-party validators. The best Google tools include Search Console's URL Inspection tool and the Rich Results Test, both of which help verify that individual URLs are crawlable and indexable. But these tools work on individual URLs, not on the sitemap file itself. You need both approaches: file-level XML validation and URL-level status verification working in tandem.
Building a Repeatable Audit Process
My recommended workflow is simple and effective. First, validate the XML structure against the sitemap protocol schema. Second, check every URL for HTTP 200 responses. Third, verify that each URL matches its canonical tag. Fourth, confirm that lastmod dates reflect actual content changes, not automated timestamps. Run this process weekly for large sites and monthly for smaller properties. Automate where possible, but always review the results manually.
Automation matters because sitemaps change constantly. Every time your CMS publishes a page, deletes a product, or updates a slug, the sitemap should reflect that change accurately. Dynamic sitemaps generated by WordPress plugins, Shopify's built-in generator, or custom scripts all introduce potential failure points. A weekly validation cadence catches drift before it accumulates into a serious indexing problem. The discipline of regular audits separates competent technical SEO from guesswork.
CMS-generated sitemaps often include non-indexable pages like tag archives or pagination URLs that waste crawl budget.
What the Counterarguments Get Wrong
The "Google Will Figure It Out" Myth
Some SEO professionals argue that sitemaps don't matter because Google discovers pages through internal links and external backlinks anyway. They're partially right. Google does use link-based discovery as its primary crawl mechanism. But this argument ignores the speed advantage that sitemaps provide. A properly formatted sitemap with accurate lastmod values tells Google exactly which pages are new or updated, skipping the discovery delay inherent in link-based crawling. For time-sensitive content like news articles or product launches, this difference is significant.
The "Google is smart enough" crowd also underestimates the scale problem. A site with 100 pages might get fully crawled through links alone. A site with 500,000 pages absolutely cannot rely on link discovery for comprehensive indexing. Google's own documentation recommends sitemaps for large sites, sites with many orphan pages, and new sites with few external links. If Google itself says sitemaps matter, dismissing them requires more evidence than a casual "it'll be fine."
Small Sites Need This Too
Another common pushback: "My site only has 50 pages, I don't need to worry about sitemap validation." This is wrong for a different reason. Small sites have less crawl budget allocated by default, which means every wasted crawl request proportionally hurts more. If your 50-page sitemap includes 5 broken URLs, that's 10% waste. On a large site, 5 broken URLs out of 50,000 is rounding error. Scale cuts both ways, and smaller sites are actually more vulnerable to sitemap errors degrading their crawl efficiency.
I've seen small business sites lose indexation on key service pages because their sitemap pointed Google to a redirected URL instead of the final destination. The canonical page existed, the content was strong, but Google's crawler kept hitting the redirect through the sitemap and eventually reduced crawl frequency for the entire domain. Fixing the sitemap restored indexation within two weeks. The problem had persisted for three months before anyone thought to check. Validation isn't a luxury for enterprise sites; it's a necessity for every site that depends on organic search.
Frequently Asked Questions
?How do I run a sitemap error check before submitting to Search Console?
?Is a sitemap index file safer than one large XML sitemap?
?How long does it take for sitemap errors to affect rankings?
?Does ignoring priority and changefreq tags actually hurt my sitemap?
Final Thoughts
Google's crawler is methodical, resource-constrained, and unforgiving of preventable errors. Your XML sitemap is your direct communication channel with that crawler, and treating it carelessly is a choice to leave rankings on the table.
Proactive sitemap validation using a reliable checker catches the errors that silently erode your indexing performance. Run the audit, fix the broken URLs, validate the XML, and submit with confidence. The sites that rank consistently are the ones that get these technical foundations right, not occasionally, but every single week.
Disclaimer: Portions of this content may have been generated using AI tools to enhance clarity and brevity. While reviewed by a human, independent verification is encouraged.